-
12/19 - pandas스파르타/TIL(Today I Learned) 2023. 12. 19. 18:03
pandas 공부 중 처음에 파일이 오류가 났다.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 3-4: truncated \UXXXXXXXX escape
여기서 오류는 \UXXXXX 부분에서 \U가 유니코드로 인식이 된다는 말이라고 한다.
해결책은 파일을 업로드하는 파일 명(즉 경로)앞에 r을 붙이고 쓴다.

r이 의미하는 것은 Raw문자열이며, 가공되지 않는 문자 그대로를 사용한다~ 라는 뜻이다.
❗ 우리가 만일 csv 파일이 아닌 text파일에 저장된 데이터를 연다고 가정하자
이때 text 파일에 쉼표로 구분 되어있으면 read_csv를 써도 잘 작동된다.
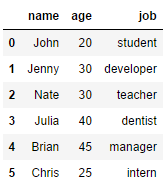
그러나 텍스트 파일에 tab으로 구분된 데이터가 있으면 다음과 같이 나온다.


우리가 원하는 데이터 형식이 아니다. 이때에는 우리가 구분자가 tab이라는것을 알려줘야한다.
deilmiter(구분 문자)가 tab이라는 것은 delimiter = '\t'라고 사용하면 된다.
❗ 만약 데이터의 header 가 없고 데이터만 있는 파일이 존재한다고 가정하자
우리가 그냥 파일 불러 read_csv를 하면 왼쪽 사진처럼 데이터의 행이 header가 되는 경우가 발생한다.
이때 우리는 header를 직접 설정해줘야 우리가 원하는 데이터 형식으로 만들 수 있다.
일단 header에 있는 데이터를 다시 values에 넣어주기 위해
header=None을 써준다.
이후 column에 직접 이름을 정해준다. df.columns = ['name','age','job']



이 방법이 귀찮고 한번에 다 끝내고 싶다? 한줄에 다 써버리면 된다.
df =pd.read_csv(r"C:\Users\kwon8\OneDrive\바탕 화면\연습자료\pandas\friend_list_no_head.csv",header=None,names=['name','age','job']) 이렇게 쓰면 한번에 쓸 수 있다.
대신 이 방법은 header의 수가 적을 때 방법이다. 많을 때는 다른 방법을 찾아봐야한다.
강의에서도 나온 dropna()에서 na가 무엇일까?라는 생각에 검색을 해보았다.
NA : Not Available , 누락된 데이터 = 결측치를 말한다.
여기에는 NaN(Not a Number) , None도 포함이 된다.
파일에 있는 NaN이나 결측치를 다른 문자열로 바꾸고 싶다면
na_rep= ' '를 쓰면 된다. 따옴표안에 원하는 문자를 적어주면 결측치를 만나면 해당 문자로 바꿔준다.
오늘의 배운 점
1. SystaxError에 대응하는법 = 경로앞에 r 써주기
2. Text파일에 Tab으로 구분되어 있는 데이터를 읽는 법 : delimiter = '\t'
3. pandas에서의 na는 Not Available
4. 검색하고 공부하니 생각외로 재밌고 기억에 남을거 같다!'스파르타 > TIL(Today I Learned)' 카테고리의 다른 글
12/21 (0) 2023.12.21 12/20-Pandas (0) 2023.12.20 12/18 (0) 2023.12.18 12/17 WIL (0) 2023.12.17 12/15 (1) 2023.12.15